
TECHNOLOGY
Core competencies
Core
competencies
competencies

Support
State-of-the-Art
DNN Algorithms
State-of-the-Art
DNN Algorithms

Best-In-Class
NPU in
AI Accuracy
NPU in
AI Accuracy

Innovative
Technology for Minimal
Memory Usage
Technology for Minimal
Memory Usage

World’s Top Power/
Performance
Efficiency in NPU
Performance
Efficiency in NPU

Easy, Fast Edge
Deployment
of Your AI Model
Deployment
of Your AI Model
PURSUING TECHNOLOGIES
PURSUING
TECHNOLOGIES
TECHNOLOGIES
We saw fast-growing number of loT devices and believed the era of Artificial Intelligence is something inevitable. To contribute our talents to the world,
we are challenging the mose power-efficient and advanced NPU (Neural Processing Unit) for loT devices.
DEEPX KEY DIFFERENTIATORS
The realistic demand for Edge AI SoCs is to deliver GPU-level AI recognition accuracy while handling the latest,
more advanced and complex deep learning algorithms at several watts or even less. DEEPX NPU SoC achieves more than 10 TOPS/W computational
efficiency with SOC power consumption of less than 3 watts while providing higher AI recognition accuracy than Nvidia Jetson.
The realistic demand for Edge AI SoCs is to deliver
GPU-level AI recognition accuracy while handling the
latest, more advanced and complex deep learning
algorithms at several watts or even less.
DEEPX NPU SoC achieves more than 10 TOPS/W
computational efficiency with SOC power consumption
of less than 3 watts while providing higher
AI recognition accuracy than Nvidia Jetson.
1. SUPPORT S-O-T-A DNN ALGORITHMS
Since AI algorithms developed, the algorithms have been getting smarter, lighter and more complex.
In spite of complexity and more computing power required, the developers want to apply the newest algorithms to their applications.
To satisfy the needs, DEEPX optimizes and supports the latest algorithms ever faster than any competitors in the market.
1.
SUPPORT S-O-T-A DNN
ALGORITHMS
Since AI algorithms developed, the algorithms have been getting smarter, lighter and more complex.
In spite of complexity and more computing power required, the developers want to apply the newest algorithms to their applications.
To satisfy the needs, DEEPX optimizes and supports the latest algorithms ever faster than any competitors in the market.
SOTA DNN Algorithms
- BiseNetv2
- ShelfNet18
- Deeplabv3
- Deeplabv3+
- PIDNet
- mnasnet
- mobilenet
- mobilenetv2
- resnet101
- resnet152
- resnet18
- resnet50
- etc
- resnext50
- squeezenet
- SSD
- YOLOv3
- YOLOv4
- YOLOv5
- YOLOv7
- YOLOx
- EfficientNet
- EfficientDet
- resnet34
2. TRULY STUNNING AI ACCURACY BEYOND THEORETICAL LIMITS2.
TRULY STUNNING AI ACCURACY
BEYOND THEORETICAL LIMITS
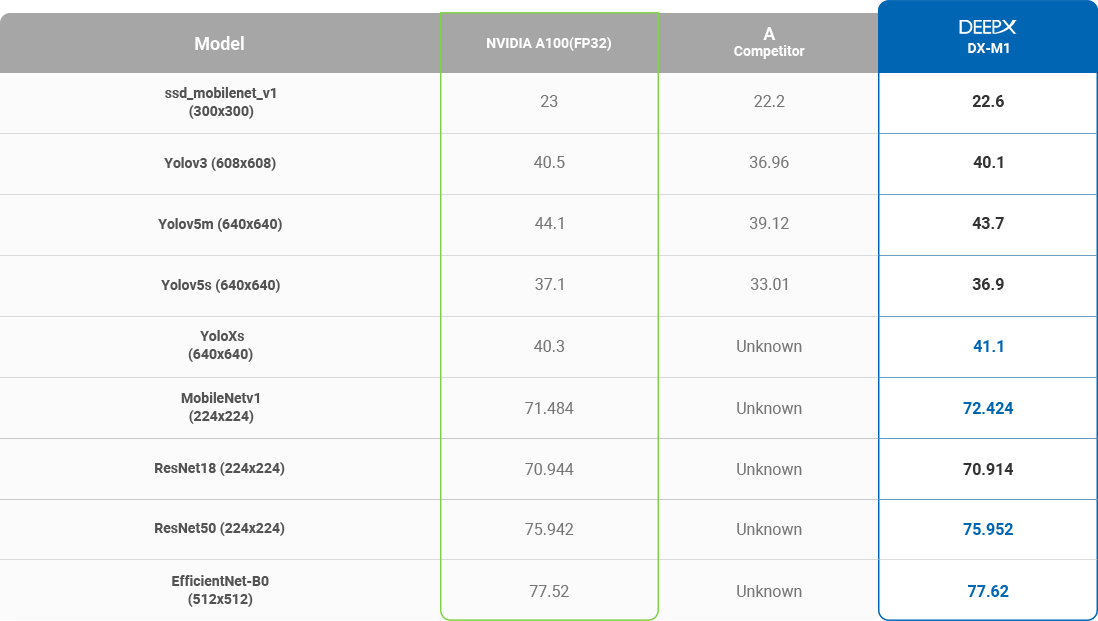
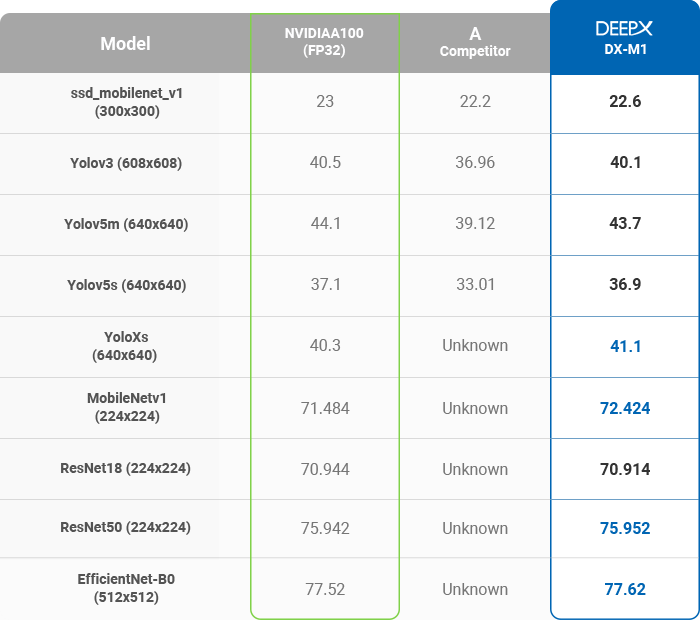
- These days many AI application DNN models are produced by GPUs. However, GPUs consume orders of magnitude power consumption that leads to overheating and reliability issues. To open the door of AI, we need cost-effective Hardware solutions when it comes to mass production and DEEPX will provide the most cost-effective and powerful AI chip for the key in the AI era.
- Many AI processors compress FP32 into Int8 in order to run AI algorithms with high power-efficiency. But they usually lose the accuracy around
5-10% in comparison with the accuracy of GPU solution using FP32 bit. Unlike other AI processors on the market, DEEPX compresses FP32 into Int8 with
the AC accuracy level of GPUs. This innovative AI technology will catalyze the pervasive AI era.
DEEPX NPU PERFORMANCE – INFERENCE ACCURACY(mAP)
DEEPX NPU PERFORMANCE –
INFERENCE ACCURACY(mAP)
INFERENCE ACCURACY(mAP)
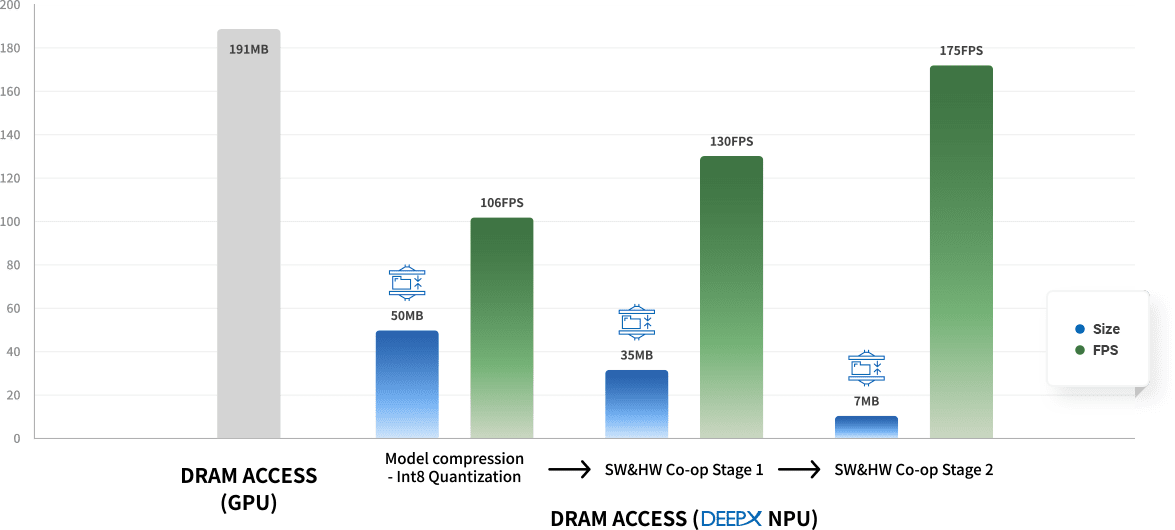
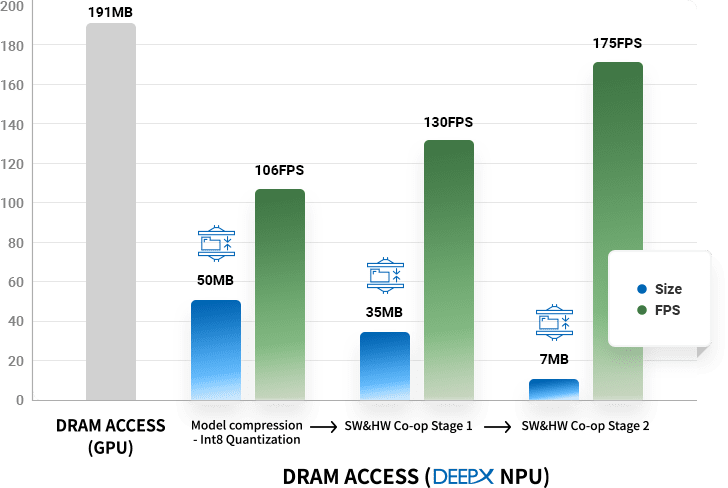
3. Minimal DRAM access and footprints of NPUs
3.
Minimal DRAM access
and footprints of NPUs
Most NPUs require a lot of DRAM access for AI processing. DRAM access consumes high power and takes a substantially long time to move data.
Therefore, reducing DRAM access greatly helps to improve the energy consumption and performance of NPUs. DEEPX has developed an innovative
technology that dramatically lowers DRAM access for AI processing. Not only GPU, but also have dramatically lower DRAM access than global
competitors.Additionally, this further helps to lower the BOM of application systems by reducing the number of DRAM devices in real applications.
4. The most power-efficient and powerful performing NPU
4.
The most power-efficient and
powerful performing NPU
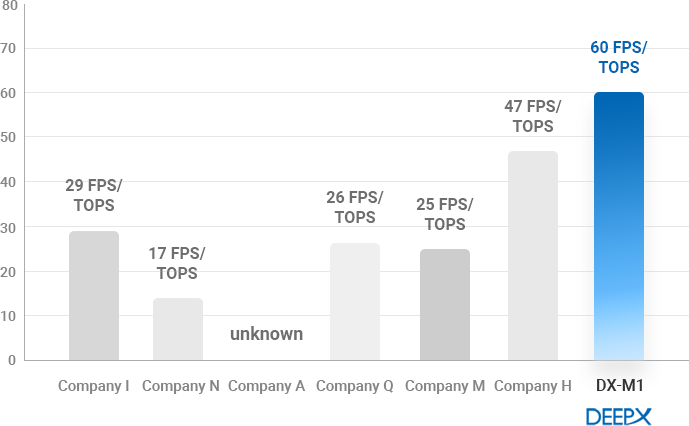
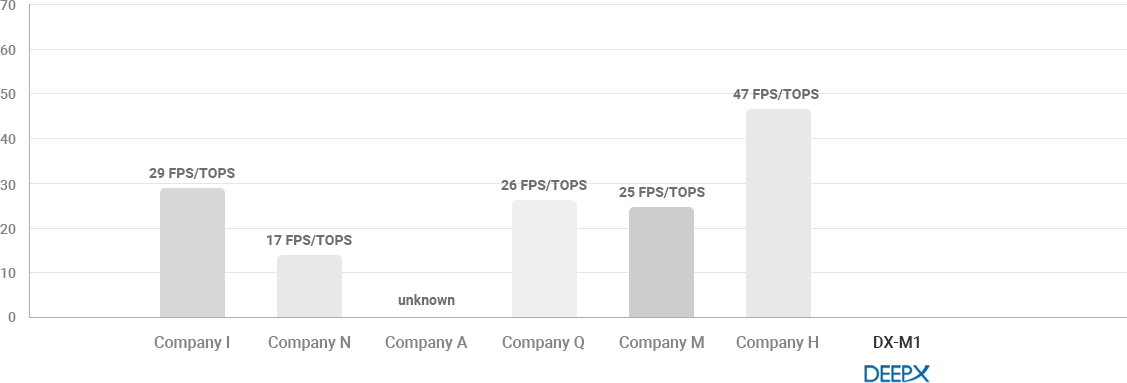
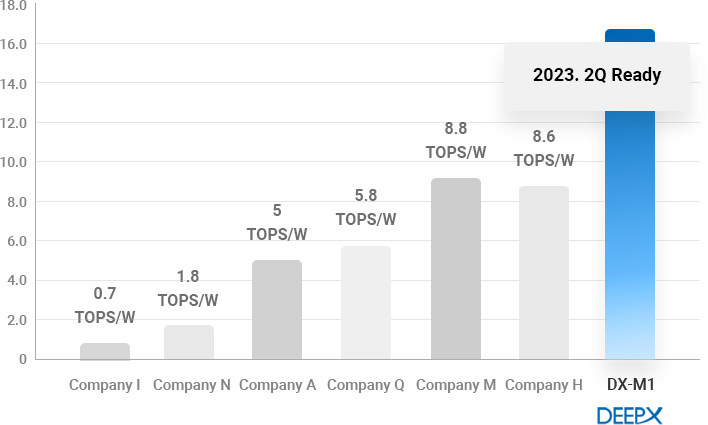
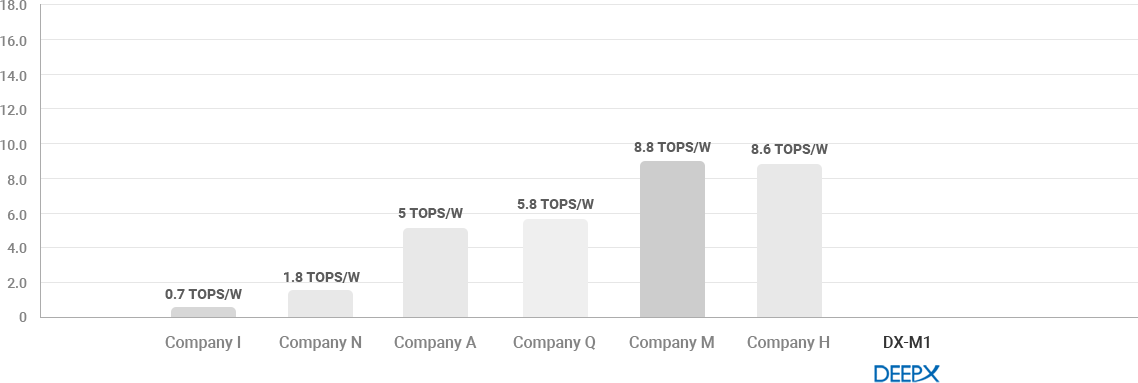
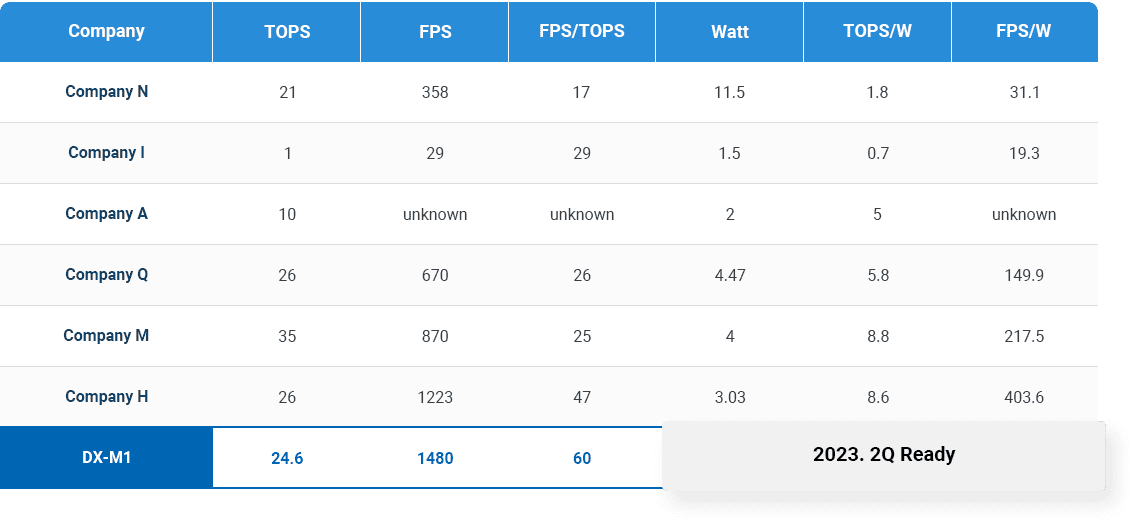
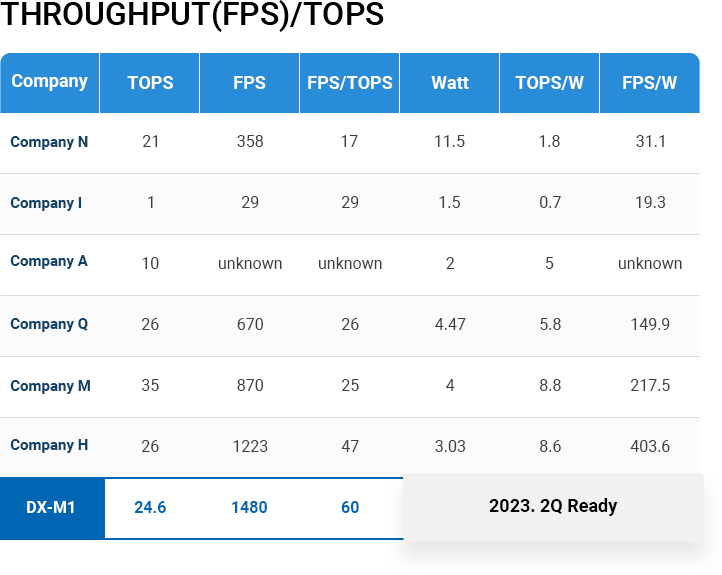
- DEEPX’s NPU technology outperforms all global top tier competitors in terms of power consumption-to performance ratio and effective performance efficiency.
- Most NPUs require a lot of DRAM access. DRAM access consumes more power and takes a substantially long time to move data.
Therefore, reducing DRAM access greatly helps to improve the energy consumption and performance of NPUs.
DEEPX has developed an innovative technology that dramatically lowers DRAM access for AI processing. Not only GPU, but also have much lower DRAM
access than global competitors. This further helps to lower the BOM of application systems by reducing the number of DRAM devices in real applications. - For power consumption-to performance ratio, we now have comparison data based on EDA tool based estimation results.
We will share details of comparison results based on the measurement of fabricated SoCs in early next year.
THROUGHPUT(FPS)/TOPS
TOPS/W
DEEPX NPU PERFORMANCE – RESNET50
5. Easy and Fast NPU Software Development Kit (DXNN)
with Integrated Development Environment
with Integrated Development Environment
The HW architecture is not only important to run an AI Algorithm efficiently but also SW stack shall come along.
DEEPX’s DXNN compiler supports various soft framework PyTorch, Tensorflow, Caffe, like other competitors.
And the most important thing is that it allows developers to port AI models to the DEEPX NPU easy and fast.
DXNN with IDE will automatically facilitate model conversion, quantization, model optimization, compilation, debugging, and profiling analysis of the model operation in NPUs.

MLPerf
Benchmark Result


APPLICATION TESTThe Video illustrates how fast 50,000 pictures from the Imagenet 2012 dataset are inferred
by the DEEPX NPU in an FPGA device.
The demo system is composed of a Windows PC and Xilinx Alveo U250 FPGA board.
The FPGA-based implementation running at 320Mhz demonstrates 600 IPS
(1.6 ms per inference) for the MobileNet Version 1 in the MLPerf AI benchmark category.
The performance implemented in an ASIC will become over three times higher without any
NPU design change because of simple clock frequency improvement
(top-ranked in the MLPerf AI benchmark).
by the DEEPX NPU in an FPGA device.
The demo system is composed of a Windows PC and Xilinx Alveo U250 FPGA board.
The FPGA-based implementation running at 320Mhz demonstrates 600 IPS
(1.6 ms per inference) for the MobileNet Version 1 in the MLPerf AI benchmark category.
The performance implemented in an ASIC will become over three times higher without any
NPU design change because of simple clock frequency improvement
(top-ranked in the MLPerf AI benchmark).
Applications
01Consumer
Electronics
Electronics

Robot
Vacuums
Vacuums

Smart TV

Smart
Air conditioner
Air conditioner




02Smart
Mobility
Mobility

Self-driving car

Drone

AMR
(Autonomous
Mobile Robot)
(Autonomous
Mobile Robot)


03Automotive

ADAS

Driver Monitoring
System
System

Infotainment
04VR/AR

Entertainment
Device
Device

Enterprise
Device
Device
Persona
Assistant
Assistant
05AI SERVER

Data Center

Edge Server

On-Premise


![]()